Як створити файл Robots.txt: налаштування, перевірка, індексація
У SEO дрібниць не буває. Іноді на просування сайту може вплинути лише один невеликий файл — Robots.txt. Якщо ви хочете, щоб ваш сайт зайшов в індекс, щоб пошукові роботи обійшли потрібні сторінки, потрібно прописати для них рекомендації.
“Хіба це можливо?” , – Запитайте ви. Можливо. Для цього на вашому сайті має бути файл robots.txt. Як правильно скласти файл роботс , налаштувати і додати на сайт – розуміємося на цій статті.
Що таке robots.txt і для чого потрібний
Robots.txt – це звичайний текстовий файл , який містить у собі рекомендації для пошукових роботів: які сторінки потрібно сканувати, а які ні.
Важливо: файл повинен бути кодований UTF-8, інакше пошукові роботи можуть його не сприйняти.
Чи зайде до індексу сайт, на якому не буде цього файлу? Зайде, але роботи можуть “вихопити” ті сторінки, наявність яких у результатах пошуку небажана: наприклад, сторінки входу, адмінпанель, особисті сторінки користувачів, сайти-дзеркала тощо. Все це вважається «пошуковим сміттям»:
Якщо результати пошуку потрапить особиста інформація, можете постраждати і ви, і сайт. Ще один момент – без цього файлу індексація сайту проходитиме довше.
У файлі Robots.txt можна задати три типи команд для пошукових павуків:
- сканування заборонено;
- сканування дозволено;
- сканування дозволено частково.
Усе це прописується з допомогою директив.
Як створити правильний файл Robots.txt для сайту
Файл Robots.txt можна створити просто в програмі Блокнот, яка за замовчуванням є на будь-якому комп’ютері. Прописування файлу займе навіть у новачка максимум півгодини (якщо знати команди).
Також можна використовувати інші програми – Notepad, наприклад. Є й онлайн-сервіси, які можуть згенерувати файл автоматично. Наприклад, такі як CY-PR.com або Mediasova .
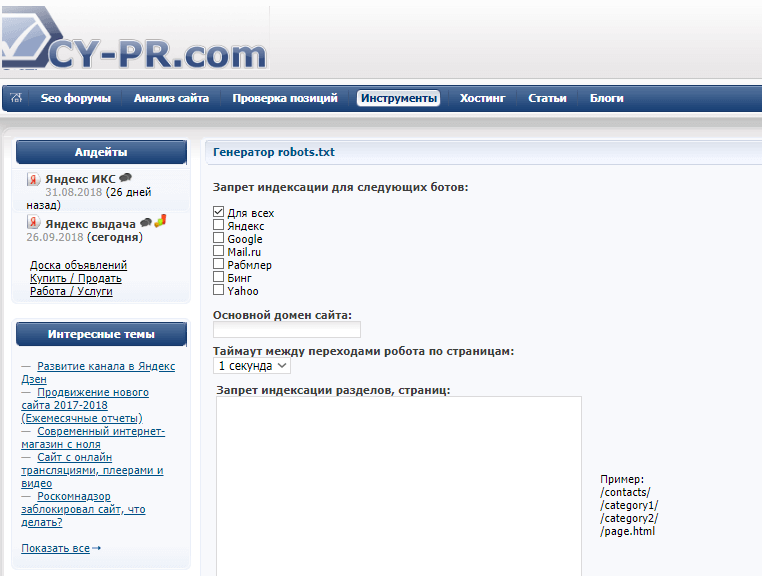
Вам просто потрібно вказати адресу свого сайту, для яких пошукових систем потрібно встановити правила, головне дзеркало (з www або без). Далі обслуговування все зробить сам.
Особисто я віддаю перевагу старому «дідовському» способу – прописати файл вручну в блокноті. Є ще й «лінивий спосіб» – спантеличити цим свого розробника 🙂 Але навіть у такому випадку ви повинні перевірити, чи правильно там все прописано. Тому давайте розберемося, як скласти цей файл, і де він повинен знаходитися.
Де повинен знаходитись файл Robots
Готовий файл Robots.txt повинен знаходитись у кореневій папці сайту. Просто файл без папки:
Бажаєте перевірити, чи є він на вашому сайті? Вбийте в адресний рядок адресу: site.ru/robots.txt . Вам відкриється ось така сторінка (якщо файл є):

Файл складається з кількох блоків, відокремлених відступом. У кожному блоці – рекомендації для пошукових роботів різних пошукових систем (плюс блок із загальними правилами для всіх), та окремий блок із посиланнями на карту сайту – Sitemap.
Усередині блоку з правилами одного пошукового робота відступи робити не потрібно.
Кожен блок починається директивою User-agent.
Після кожної директиви ставиться знак “:” (двокрапка), пробіл, після якого вказується значення (наприклад, яку сторінку закрити від індексації).
Потрібно вказувати відносні адреси сторінок, а чи не абсолютні. Відносні – це без www.site.ru. Наприклад, вам потрібно заборонити до індексації сторінку www.site.ru/shop . Значить після двокрапки ставимо прогалину, слеш і «shop»:
Disallow: /shop.
Зірочка (*) означає будь-який набір символів.
Знак долара ($) – кінець рядка.
Ви можете вирішити – навіщо писати файл із нуля, якщо його можна відкрити на будь-якому сайті та просто скопіювати собі?
Для кожного сайту необхідно прописувати унікальні правила. Потрібно врахувати особливості CMS . Наприклад, та сама адмінпанель знаходиться за адресою /wp-admin на движку WordPress, на іншій адресі буде відрізнятися. Те саме з адресами окремих сторінок, з картою сайту та іншим.
Налаштування файлу Robots.txt: індексація, головне дзеркало, директиви
Як ви вже бачили на скріншоті, першою йде директива User-agent. Вона вказує, для якого пошукового робота будуть правила нижче.
User-agent: * – правила для всіх пошукових роботів, тобто будь-якої пошукової системи (Google, Yandex, Bing, Рамблер тощо).
User-agent: Googlebot – вказує на правила пошуку павука Google.
User-agent: Yandex – правила пошуку Яндекс.
Для якого пошукового робота прописувати правила першим, немає жодної різниці. Але зазвичай спочатку пишуть поради для всіх роботів.
Рекомендації для кожного робота, як я вже писала, відокремлюються відступом.
Disallow: Заборона на індексацію
Для заборони індексації сайту в цілому або окремих сторінок використовується директива Disallow.
Наприклад, ви можете повністю закрити сайт від індексації (якщо ресурс знаходиться на доопрацюванні і ви не хочете, щоб він потрапив у видачу в такому стані). Для цього потрібно прописати таке:
User-agent: *
Disallow: /
Таким чином, усім пошуковим роботам заборонено індексувати контент на сайті.
А ось так можна відкрити сайт для індексації:
User-agent: *
Disallow:
Тому перевірте, чи варто сліш після директиви Disallow, якщо хочете закрити сайт. Якщо хочете потім його відкрити – не забудьте зняти правило (а так часто трапляється).
Щоб закрити від індексації окремі сторінки, потрібно вказати їхню адресу. Я вже писала, як це робиться:
User-agent: *
Disallow: /wp-admin
Таким чином, на сайті закрили від сторонніх поглядів адмінпанель.
Що потрібно закривати від індексації обов’язково:
- адміністративну панель;
- особисті сторінки користувачів;
- кошики;
- результати пошуку на сайті;
- сторінки входу, реєстрації, авторизації.
Можна закрити від індексації та окремі типи файлів. Припустимо, у вас на сайті є деякі PDF-файли, індексація яких небажана. А пошукові роботи дуже легко сканують залиті на сайт файли. Закрити їх від індексації можна так:
User-agent: *
Disallow: /*. pdf$
Як відкрити сайт для індексації
Навіть при повністю закритому від індексації сайті можна відкрити роботам шлях до певних файлів або сторінок. Допустимо, ви переробляєте сайт, але каталог із послугами залишається недоторканим. Ви можете надіслати пошукові роботи туди, щоб вони продовжували індексувати розділ. Для цього використовується директива Allow:
User-agent: *
Allow: /uslugi
Disallow: /
Головне дзеркало сайту
До 20 березня 2018 року у файлі robots.txt для пошукового робота Яндекс потрібно було вказувати головне дзеркало сайту через директиву Host. Наразі цього робити не потрібно – достатньо налаштувати посторінковий 301-редирект .
Що таке головне дзеркало? Це яка адреса вашого сайту є головною – з www або без. Якщо не налаштувати редирект, то обидва сайти будуть проіндексовані, тобто дублі всіх сторінок.
Карта сайту: robots.txt sitemap
Після того, як прописані всі директиви для роботів, необхідно вказати шлях до Sitemap. Карта сайту показує роботам, що всі URL-адреси, які потрібно проіндексувати, знаходяться за певною адресою. Наприклад:
Sitemap: site.ru/sitemap.xml
Коли робот обходитиме сайт, він бачитиме, які зміни вносилися до цього файлу. У результаті нові сторінки індексуватимуться швидше.
Директива Clean-param
2009 року Яндекс ввів нову директиву – Clean-param. З її допомогою можна описати динамічні параметри, які впливають зміст сторінок. Найчастіше ця директива використовується на форумах. Тут з’являється багато сміття, наприклад id сесії, параметри сортування. Якщо прописати цю директиву, пошуковий робот Яндекса не багато разів завантажуватиме інформацію, яка дублюється.
Прописати цю директиву можна будь-де файлу robots.txt.
Параметри, які роботу не потрібно враховувати, перераховуються у першій частині значення через знак &:
Clean-param: sid&sort /forum/viewforum.php
Ця директива дозволяє уникнути дублів сторінок із динамічними адресами (які містять знак питання).
Директива Crawl-delay
Ця директива допоможе тим, у кого слабкий сервер.
Прихід пошукового робота – це додаткове навантаження на сервер. Якщо у вас висока відвідуваність сайту, то ресурс може не витримати і «лягти». У результаті робота отримає повідомлення про помилку 5хх. Якщо така ситуація повторюватиметься постійно, сайт може бути визнаний пошуковою системою неробочим.
Уявіть, що ви працюєте і паралельно вам доводиться постійно відповідати на дзвінки. Ваша продуктивність у разі падає.
Так само і з сервером.
Повернімося до директиви. Crawl-delay дозволяє встановити затримку сканування сторінок сайту з метою знизити навантаження на сервер. Іншими словами, ви задаєте період, через який завантажуватимуться сторінки сайту. Вказується цей параметр у секундах, цілим числом:
Crawl-delay: 2
Коментарі в robots.txt
Трапляються випадки, коли вам потрібно залишити у файлі коментар для інших вебмайстрів. Наприклад, якщо ресурс передається в роботу іншій команді або над сайтом працює ціла команда.
У цьому файлі, як і в інших, можна залишати коментарі для інших розробників.
Робиться це просто – перед повідомленням потрібно поставити знак ґрат: «#». Далі ви можете писати свою примітку, робот не враховуватиме написане:
User-agent: *
Disallow: /*. xls$
#закрив прайси від індексації
Як перевірити файл robots.txt
Після того, як файл написано, потрібно дізнатись, чи правильно. Для цього ви можете використовувати інструменти від Яндекс та Google.
Через Яндекс.Вебмастер robots.txt можна перевірити на вкладці «Інструменти – Аналіз robots.txt»:
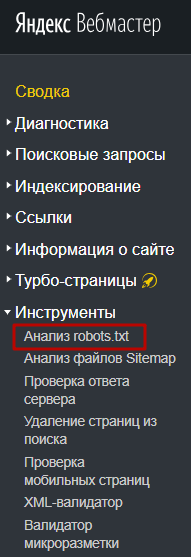
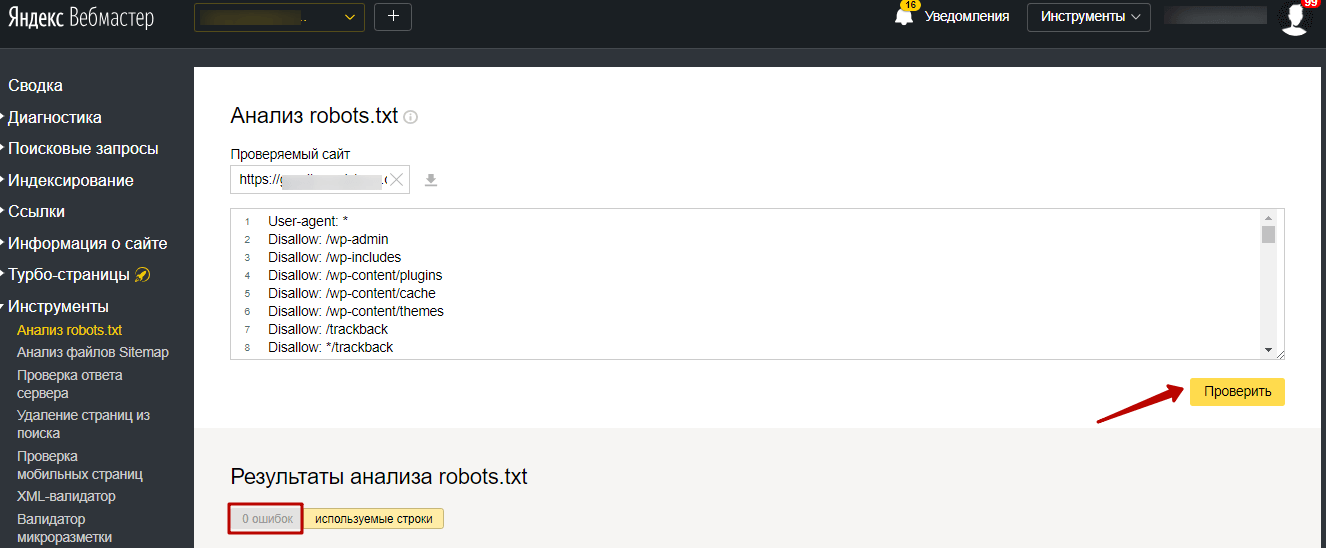
На сторінці вказуємо адресу сайту, що перевіряється, а в поле знизу вставляємо вміст свого файлу. Потім натискаємо “Перевірити”. Сервіс перевірить ваш файл і вкаже на можливі помилки:
Також можна перевірити файл robots.txt через Google Search Console, якщо у вас підтверджено права на сайт.
Для цього на панелі інструментів вибираємо «Сканування – Інструмент перевірки файлу robots.txt».
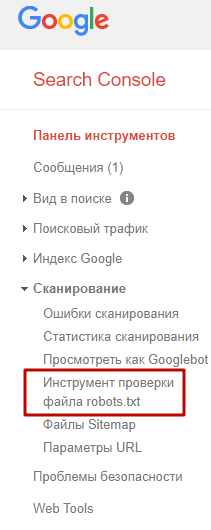
На сторінці перевірки вам також потрібно буде скопіювати і вставити вміст файлу, потім вказати адресу сайту:
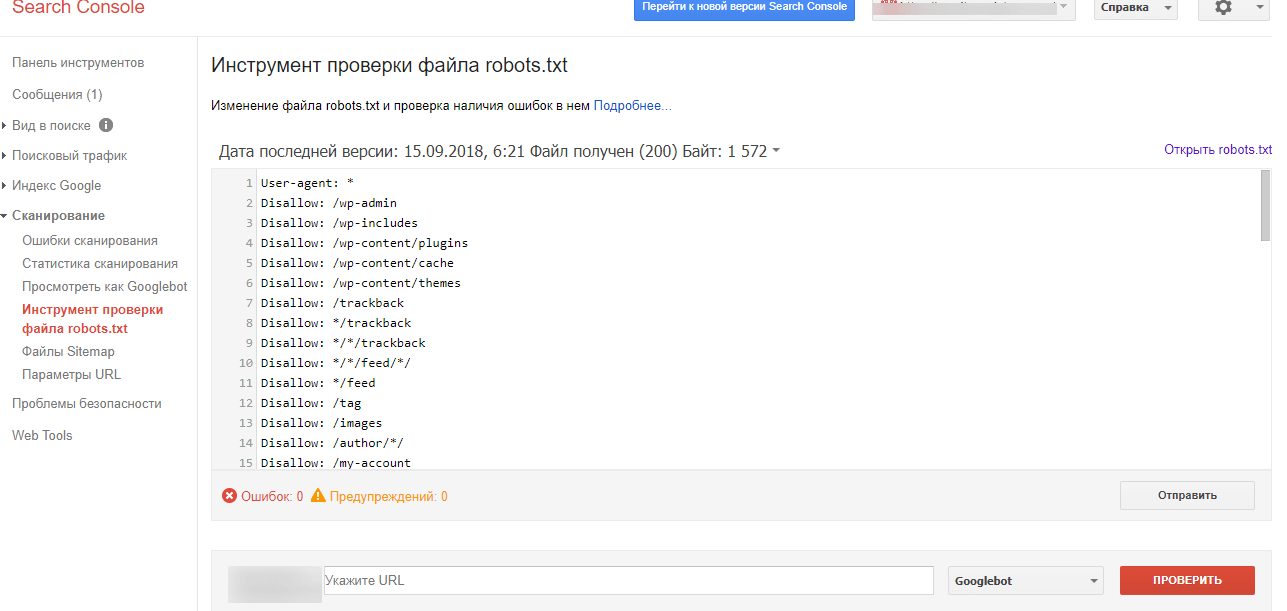
Потім натискаєте “Перевірити” – і все. Система вкаже помилки або видасть попередження.
Залишиться лише внести необхідні редагування.
Якщо у файлі є якісь помилки, або з’являться з часом (наприклад, після якоїсь чергової зміни), інструменти для вебмайстрів надсилатимуть вам повідомлення про це. Повідомлення ви побачите відразу, як увійдете в консоль.
Часті помилки у заповненні файлу robots.txt
Які ж помилки найчастіше припускаються вебмайстрами або власниками ресурсів?
1. Файлу взагалі немає. Це зустрічається найчастіше і виявляється при SEO-аудиті ресурсу. Як правило, на той момент вже помітно, що сайт індексується не так швидко, як хотілося б, або в індекс потрапили сміття.
2. Перерахуйте кілька папок або директорій в одній інструкції. Тобто ось так:
Allow: /catalog/uslugi/shop
Називається “навіщо писати більше …”. У такому разі робот взагалі не знає, що можна індексувати. Кожна інструкція повинна йти з нового рядка, заборона або дозвіл на індексацію кожної папки чи сторінки – це окрема рекомендація.
3. Різні регістри . Назва файлу має бути з маленької літери та написана маленькими літерами – жодного капса. Те саме стосується і інструкцій: кожна з великої літери, решта – маленькими. Якщо ви напишете капсом, це вважатиметься вже зовсім іншою директивою.
4. Порожній User-agent. Потрібно обов’язково вказати для якої пошукової системи йде набір правил. Якщо для всіх – ставимо зірочку, але ніяк не можна залишати пусте місце.
5. Забули відкрити ресурс для індексації після всіх робіт – просто не прибрали сліш після Disallow.
6. Зайві зірочки, прогалини, інші знаки. Це просто неуважність.
Регулярно зазирайте в інструменти для вебмайстрів та вчасно виправляйте можливі помилки у файлі robots.txt.
Вдалого вам просування!